Powerjob 笔记
1.powerjob容器部署
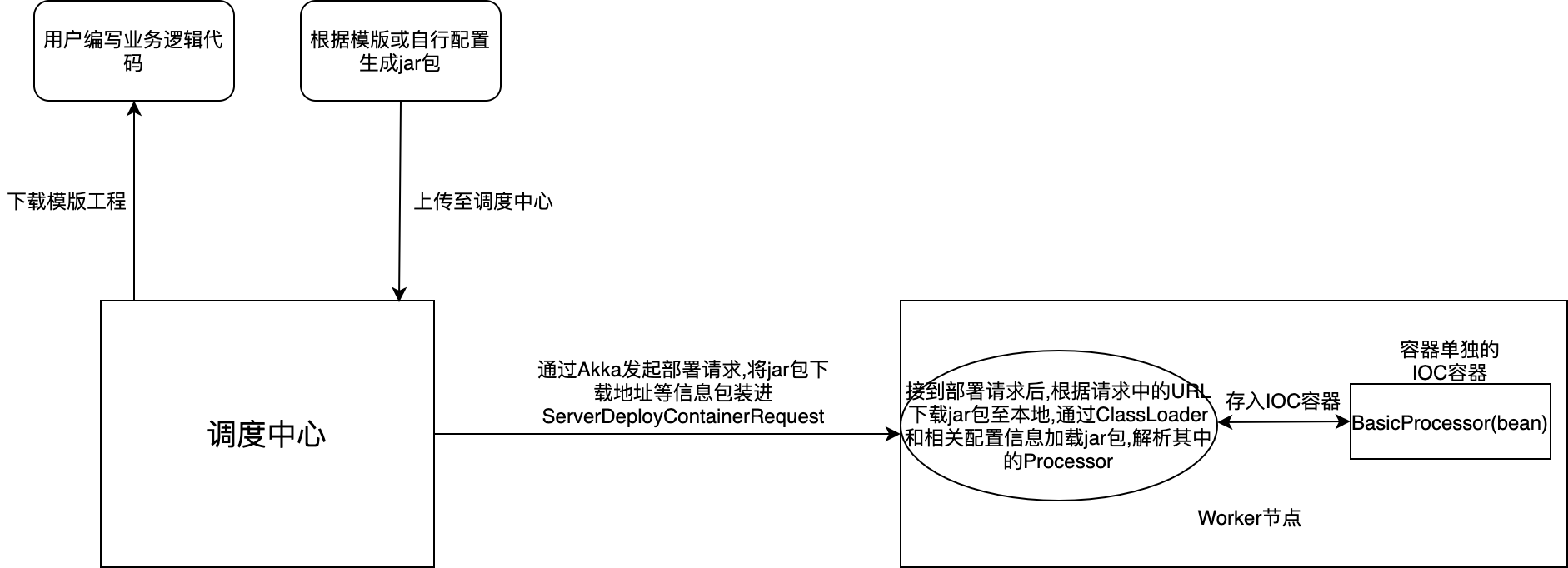
powerjob容器部署方案:
用户通过下载模版工程,创建最小化任务执行单元:
MyHandler内部仅需要实现BasicProcessor则可成为一个任务:
由于powerjob基于应用分组的思想,用户通过应用名称注册登入后,通过调度中心部署至该应用的的worker节点
容器上传至worker节点后,其相当于一个单独的执行单元,只需要在任务调度时指定Java Container模式(即上传的jar包)即可和普通任务调度方式一致
其具体部署细节:
//在worker节点接到调度中心请求后, 进行容器部署(即加载jar包)
public static synchronized void deployContainer(ServerDeployContainerRequest request) {
//...
OmsContainer oldContainer = CARGO.get(containerId);
//...
try {
if (!jarFile.exists()) {
FileUtils.forceMkdirParent(jarFile);
//从URL下载至本地
FileUtils.copyURLToFile(new URL(request.getDownloadURL()), jarFile, 5000, 300000);
log.info("[OmsContainer-{}] download jar successfully, path={}", containerId, jarFile.getPath());
}
// 创建新容器
OmsContainer newContainer = new OmsJarContainer(containerId, containerName, version, jarFile);
//具体容器加载机制,如内部使用Spring的ApplicationContext加载我们写的MyHandler
newContainer.init();
// 替换容器 这里很重要, 此处相当于一个将该容器放入一个工厂中,之后调用改容器仅需通过CARGO获得即可
CARGO.put(containerId, newContainer);
log.info("[OmsContainer-{}] deployed new version:{} successfully!", containerId, version);
if (oldContainer != null) {
// 销毁旧容器
oldContainer.destroy();
}
} catch (Exception e) {
log.error("[OmsContainer-{}] deployContainer(name={},version={}) failed.", containerId, containerName, version, e);
// 如果部署失败,则删除该 jar(本次失败可能是下载jar出错导致,不删除会导致这个版本永久无法重新部署)
CommonUtils.executeIgnoreException(() -> FileUtils.forceDelete(jarFile));
}
}
//OmsJarContainer具体加载jar方式
public void init() throws Exception {
log.info("[OmsJarContainer-{}] start to init container(name={},jarPath={})", containerId, name, localJarFile.getPath());
URL jarURL = localJarFile.toURI().toURL();
// 创建类加载器(父类加载为 Worker 的类加载)
this.containerClassLoader = new OhMyClassLoader(new URL[]{jarURL}, this.getClass().getClassLoader());
// 解析 Properties, 该properteis为模版工程里的oms-worker-container.properties, 目的是为了获得MyHandler的包名
Properties properties = new Properties();
try (InputStream propertiesURLStream = containerClassLoader.getResourceAsStream(ContainerConstant.CONTAINER_PROPERTIES_FILE_NAME)) {
if (propertiesURLStream == null) {
log.error("[OmsJarContainer-{}] can't find {} in jar {}.", containerId, ContainerConstant.CONTAINER_PROPERTIES_FILE_NAME, localJarFile.getPath());
throw new PowerJobException("invalid jar file because of no " + ContainerConstant.CONTAINER_PROPERTIES_FILE_NAME);
}
properties.load(propertiesURLStream);
log.info("[OmsJarContainer-{}] load container properties successfully: {}", containerId, properties);
}
//取得MyHandler的包名
String packageName = properties.getProperty(ContainerConstant.CONTAINER_PACKAGE_NAME_KEY);
if (StringUtils.isEmpty(packageName)) {
log.error("[OmsJarContainer-{}] get package name failed, developer should't modify the properties file!", containerId);
throw new PowerJobException("invalid jar file");
}
// 加载用户类
containerClassLoader.load(packageName);
// 创建 Spring IOC 容器(Spring配置文件需要填相对路径)
// 需要切换线程上下文类加载器以加载 JDBC 类驱动(SPI)
ClassLoader oldCL = Thread.currentThread().getContextClassLoader();
Thread.currentThread().setContextClassLoader(containerClassLoader);
try {
this.container = new ClassPathXmlApplicationContext(new String[]{ContainerConstant.SPRING_CONTEXT_FILE_NAME}, false);
this.container.setClassLoader(containerClassLoader);
//到此处MyHandler已经被注册为IOC容器中的一个bean,只需在任务执行时通过判断执行类型为Java Container是通过上面的工厂里获取MyHandler即可执行相应逻辑
this.container.refresh();
}finally {
Thread.currentThread().setContextClassLoader(oldCL);
}
log.info("[OmsJarContainer-{}] init container(name={},jarPath={}) successfully", containerId, name, localJarFile.getPath());
}
2.powerjob任务传参实现方式
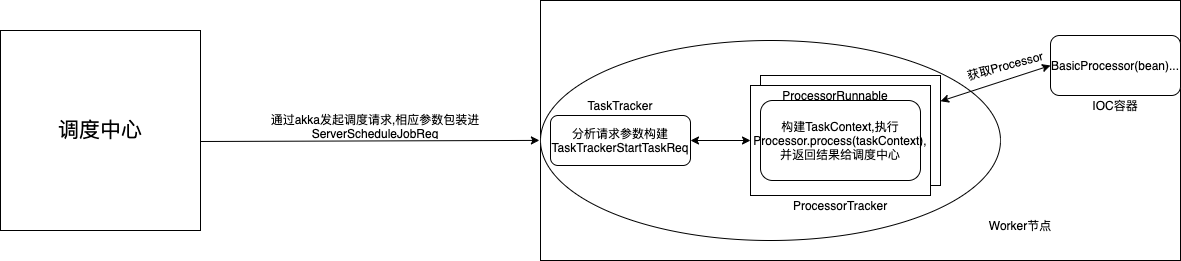 具体到最终我们实现的BasicProcessor有两处重要的地方,
具体到最终我们实现的BasicProcessor有两处重要的地方,
一是根据调度中心发起调度请求时指定的ProcessorType构建真实运行的processor,具体代码逻辑在初始化ProcessorTracker时:
private void initProcessor() throws Exception {
ProcessorType processorType = ProcessorType.valueOf(instanceInfo.getProcessorType());
String processorInfo = instanceInfo.getProcessorInfo();
switch (processorType) {
//此处为我们直接在项目中实现的BasicProcessor
case EMBEDDED_JAVA:
// 先使用 Spring 加载
if (SpringUtils.supportSpringBean()) {
try {
processor = SpringUtils.getBean(processorInfo);
}catch (Exception e) {
log.warn("[ProcessorTracker-{}] no spring bean of processor(className={}), reason is {}.", instanceId, processorInfo, ExceptionUtils.getMessage(e));
}
}
// 反射加载
if (processor == null) {
processor = ProcessorBeanFactory.getInstance().getLocalProcessor(processorInfo);
}
break;
//执行Shell脚本使用的内置Processor
case SHELL:
processor = new ShellProcessor(instanceId, processorInfo, instanceInfo.getInstanceTimeoutMS());
break;
//执行Python脚本使用的内置Processor
case PYTHON:
processor = new PythonProcessor(instanceId, processorInfo, instanceInfo.getInstanceTimeoutMS());
break;
//我们通过调度中心部署至该worker的Processor(jar包部署)
case JAVA_CONTAINER:
String[] split = processorInfo.split("#");
log.info("[ProcessorTracker-{}] try to load processor({}) in container({})", instanceId, split[1], split[0]);
omsContainer = OmsContainerFactory.fetchContainer(Long.valueOf(split[0]), true);
if (omsContainer != null) {
processor = omsContainer.getProcessor(split[1]);
}else {
log.warn("[ProcessorTracker-{}] load container failed.", instanceId);
}
break;
default:
log.warn("[ProcessorTracker-{}] unknown processor type: {}.", instanceId, processorType);
throw new PowerJobException("unknown processor type of " + processorType);
}
if (processor == null) {
log.warn("[ProcessorTracker-{}] fetch Processor(type={},info={}) failed.", instanceId, processorType, processorInfo);
throw new PowerJobException("fetch Processor failed, please check your processorType and processorInfo config");
}
}
二是在ProcessorRunnable中通过InstancesInfo构建TaskContext,作为Processor.process(TaskContext context)的方法入参:
public void innerRun() throws InterruptedException {
//...
// 0. 完成执行上下文准备 & 上报执行信息
TaskContext taskContext = new TaskContext();
BeanUtils.copyProperties(task, taskContext);
taskContext.setJobId(instanceInfo.getJobId());
taskContext.setMaxRetryTimes(instanceInfo.getTaskRetryNum());
taskContext.setCurrentRetryTimes(task.getFailedCnt());
taskContext.setJobParams(instanceInfo.getJobParams());
taskContext.setInstanceParams(instanceInfo.getInstanceParams());
taskContext.setOmsLogger(omsLogger);
if (task.getTaskContent() != null && task.getTaskContent().length > 0) {
taskContext.setSubTask(SerializerUtils.deSerialized(task.getTaskContent()));
}
taskContext.setUserContext(OhMyWorker.getConfig().getUserContext());
ThreadLocalStore.setTask(task);
reportStatus(TaskStatus.WORKER_PROCESSING, null, null);
//....广播任务相关....
try {
// 正式提交运行, 此处是最终执行我们想要执行的任务方法
processResult = processor.process(taskContext);
}catch (Throwable e) {
log.warn("[ProcessorRunnable-{}] task(id={},name={}) process failed.", instanceId, taskContext.getTaskId(), taskContext.getTaskName(), e);
processResult = new ProcessResult(false, e.toString());
}
//上报调度中心执行结果
reportStatus(processResult.isSuccess() ? TaskStatus.WORKER_PROCESS_SUCCESS : TaskStatus.WORKER_PROCESS_FAILED, suit(processResult.getMsg()), null);
}
3.Powerjob秒级任务(FIX_RATE, FIX_DELAY)、通用任务(CRON)调度方式
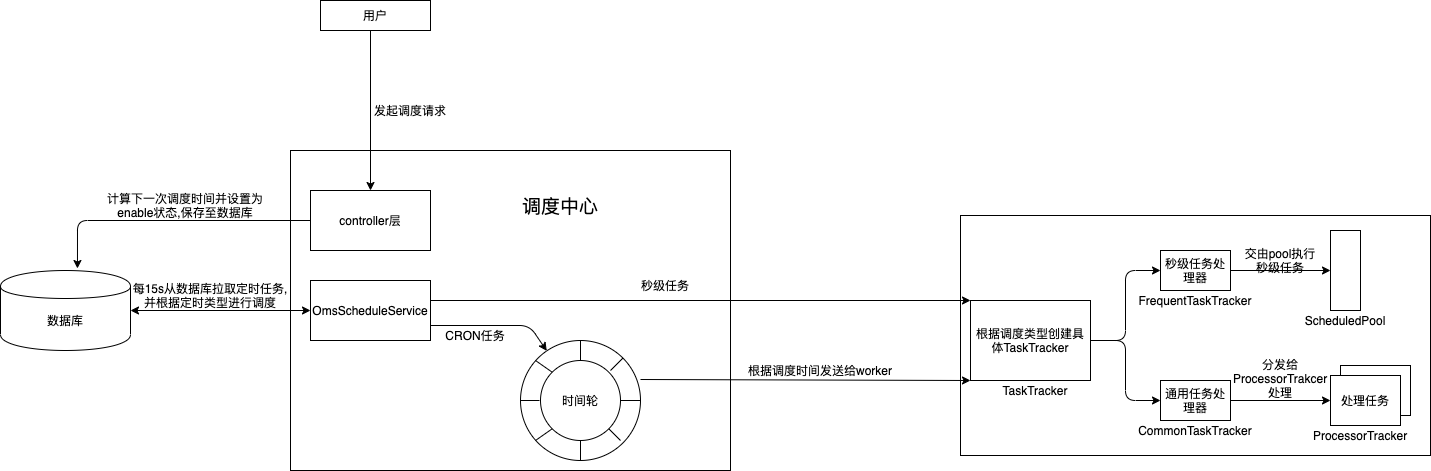 区分秒级任务和通用任务的区别, 秒级任务调度频率高, 如果有一个任务每1s执行, 那如果从调度中心统一调度, 那光是从调度中心向worker节点发送请求的时间都已经花费超过1秒了
所以powerjob在处理秒级任务时直接将定时任务下发给worker节点由worker节点自行处理, 只需按时上报任务状态即可,
而通用任务由于执行频率不高, 有些可能是每天执行一次, 每周执行一次, 而这些低频率的任务则由调度中心统一调度, 减轻worker端压力, 达到分布式任务调度的效果
powerjob中处理秒级任务(FIX_RATE)、通用任务(CRON)具体实现类: com.github.kfcfans.powerjob.server.service.timing.schedule.OmsScheduleService:
区分秒级任务和通用任务的区别, 秒级任务调度频率高, 如果有一个任务每1s执行, 那如果从调度中心统一调度, 那光是从调度中心向worker节点发送请求的时间都已经花费超过1秒了
所以powerjob在处理秒级任务时直接将定时任务下发给worker节点由worker节点自行处理, 只需按时上报任务状态即可,
而通用任务由于执行频率不高, 有些可能是每天执行一次, 每周执行一次, 而这些低频率的任务则由调度中心统一调度, 减轻worker端压力, 达到分布式任务调度的效果
powerjob中处理秒级任务(FIX_RATE)、通用任务(CRON)具体实现类: com.github.kfcfans.powerjob.server.service.timing.schedule.OmsScheduleService:
//通用任务处理
private void scheduleCronJob(List<Long> appIds) {
long nowTime = System.currentTimeMillis();
long timeThreshold = nowTime + 2 * SCHEDULE_RATE;
Lists.partition(appIds, MAX_APP_NUM).forEach(partAppIds -> {
try {
// 查询条件:任务开启 + 使用CRON表达调度时间 + 指定appId + 即将需要调度执行
List<JobInfoDO> jobInfos = jobInfoRepository.findByAppIdInAndStatusAndTimeExpressionTypeAndNextTriggerTimeLessThanEqual(partAppIds, SwitchableStatus.ENABLE.getV(), TimeExpressionType.CRON.getV(), timeThreshold);
//...
// 1. 批量写日志表
//...
// 2. 推入时间轮中等待调度执行
jobInfos.forEach(jobInfoDO -> {
Long instanceId = jobId2InstanceId.get(jobInfoDO.getId());
long targetTriggerTime = jobInfoDO.getNextTriggerTime();
long delay = 0;
if (targetTriggerTime < nowTime) {
log.warn("[Job-{}] schedule delay, expect: {}, current: {}", jobInfoDO.getId(), targetTriggerTime, System.currentTimeMillis());
}else {
delay = targetTriggerTime - nowTime;
}
InstanceTimeWheelService.schedule(instanceId, delay, () -> {
dispatchService.dispatch(jobInfoDO, instanceId, 0, null, null);
});
});
// 3. 计算下一次调度时间(忽略5S内的重复执行,即CRON模式下最小的连续执行间隔为 SCHEDULE_RATE ms)
jobInfos.forEach(jobInfoDO -> {
try {
refreshJob(jobInfoDO);
} catch (Exception e) {
log.error("[Job-{}] refresh job failed.", jobInfoDO.getId(), e);
}
});
jobInfoRepository.flush();
}catch (Exception e) {
log.error("[CronScheduler] schedule cron job failed.", e);
}
});
}
//处理秒级任务
private void scheduleFrequentJob(List<Long> appIds) {
Lists.partition(appIds, MAX_APP_NUM).forEach(partAppIds -> {
try {
// 查询所有的秒级任务(只包含ID)
List<Long> jobIds = jobInfoRepository.findByAppIdInAndStatusAndTimeExpressionTypeIn(partAppIds, SwitchableStatus.ENABLE.getV(), TimeExpressionType.frequentTypes);
//...
// 查询日志记录表中是否存在相关的任务
//...
List<Long> notRunningJobIds = Lists.newLinkedList();
jobIds.forEach(jobId -> {
if (!runningJobIdSet.contains(jobId)) {
notRunningJobIds.add(jobId);
}
});
//...
log.info("[FrequentScheduler] These frequent jobs will be scheduled: {}.", notRunningJobIds);
notRunningJobIds.forEach(jobId -> {
Optional<JobInfoDO> jobInfoOpt = jobInfoRepository.findById(jobId);
//此处直接调用jobService.runJob, 相当于web端点击执行一次按钮, 调度中心无需调度, 执行压力交给worker节点
jobInfoOpt.ifPresent(jobInfoDO -> jobService.runJob(jobInfoDO.getAppId(), jobId, null, 0L));
});
}catch (Exception e) {
log.error("[FrequentScheduler] schedule frequent job failed.", e);
}
});
}
4.powerjob-worker端任务分发原理
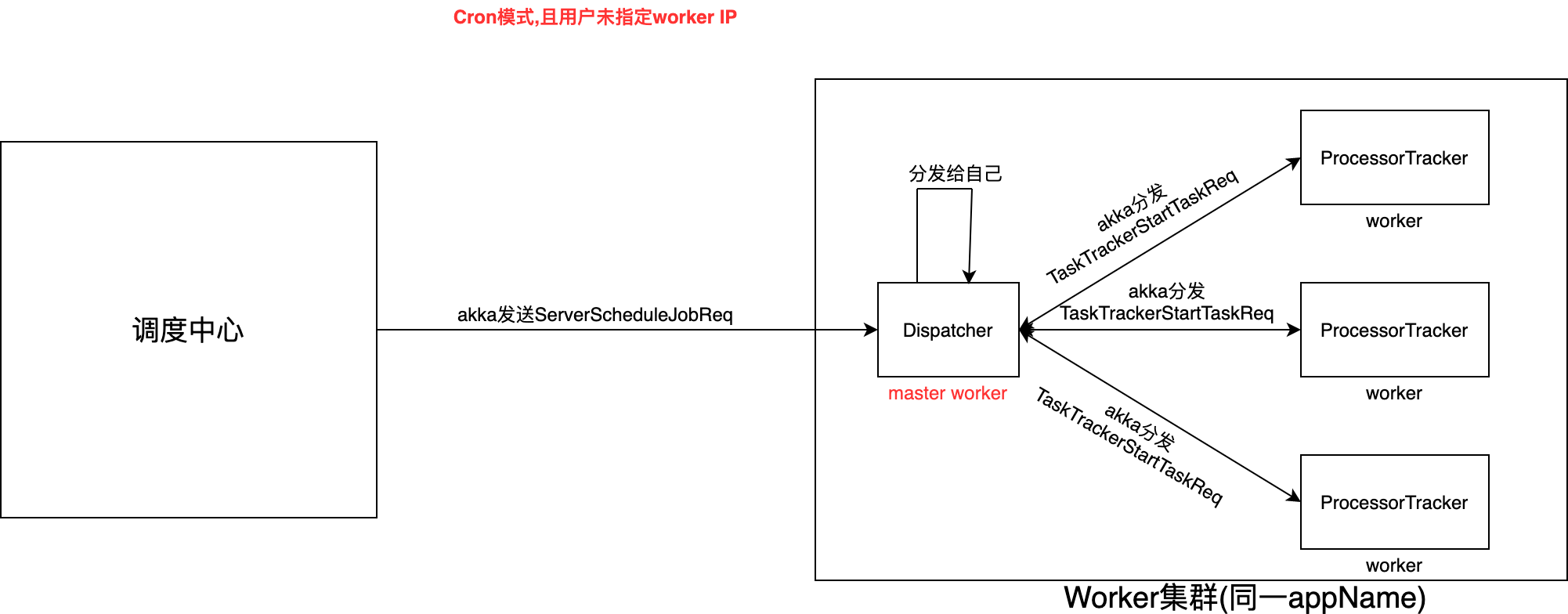 powerjob使用AppName分组, 那么worker端就可以通过配置相同的appName来部署worker集群, 而在调度中心分发任务时, 则需要一个机制来确定如何分发任务到集群中
powerjob使用AppName分组, 那么worker端就可以通过配置相同的appName来部署worker集群, 而在调度中心分发任务时, 则需要一个机制来确定如何分发任务到集群中
首先当我们指定该app集群中某一个worker时, 即新建任务时写入某个worker IP,此时则用户自己明确该任务由当前worker(ip指定的worker)去执行.
 当该地址为空时,默认为该app下全部worker均需要接受这个调度任务, 那么此时就需要一种手段去分发这些任务:而powerjob将分发能力交给worker处理
当该地址为空时,默认为该app下全部worker均需要接受这个调度任务, 那么此时就需要一种手段去分发这些任务:而powerjob将分发能力交给worker处理
powerjob使用第一个可使用的worker为master, 最终由master(worker)去分发任务至该集群中所有worker:
powerjob选主源码:
public void dispatch(JobInfoDO jobInfo, long instanceId, long currentRunningTimes, String instanceParams, Long wfInstanceId) {
//....一些前置检测
// 获取当前所有可用的Worker
List<WorkerInfo> allAvailableWorker = WorkerClusterManagerService.getSortedAvailableWorkers(jobInfo.getAppId(), jobInfo.getMinCpuCores(), jobInfo.getMinMemorySpace(), jobInfo.getMinDiskSpace());
//过滤空worker和不属于该appName下的集群worker
allAvailableWorker.removeIf(worker -> {
// 空,则全部不过滤
if (StringUtils.isEmpty(jobInfo.getDesignatedWorkers())) {
return false;
}
// 非空,只有匹配上的 worker 才不被过滤
Set<String> designatedWorkers = Sets.newHashSet(commaSplitter.splitToList(jobInfo.getDesignatedWorkers()));
return !designatedWorkers.contains(worker.getAddress());
});
//...
// 限定集群大小(0代表不限制)
if (jobInfo.getMaxWorkerCount() > 0) {
if (allAvailableWorker.size() > jobInfo.getMaxWorkerCount()) {
allAvailableWorker = allAvailableWorker.subList(0, jobInfo.getMaxWorkerCount());
}
}
List<String> workerIpList = allAvailableWorker.stream().map(WorkerInfo::getAddress).collect(Collectors.toList());
// 构造请求
ServerScheduleJobReq req = new ServerScheduleJobReq();
//...填充req
// 发送请求(不可靠,需要一个后台线程定期轮询状态)
// 此处设置第一个可用的worker为master worker
WorkerInfo taskTracker = allAvailableWorker.get(0);
String taskTrackerAddress = taskTracker.getAddress();
//向master worker发起任务请求
transportService.tell(Protocol.of(taskTracker.getProtocol()), taskTrackerAddress, req);
log.info("[Dispatcher-{}|{}] send schedule request to TaskTracker[protocol:{},address:{}] successfully: {}.", jobId, instanceId, taskTracker.getProtocol(), taskTrackerAddress, req);
// 修改状态
instanceInfoRepository.update4TriggerSucceed(instanceId, WAITING_WORKER_RECEIVE.getV(), currentRunningTimes + 1, current, taskTrackerAddress, dbInstanceParams, now);
// 装载缓存
instanceMetadataService.loadJobInfo(instanceId, jobInfo);
}
当请求到达master worker时, worker根据调度类型创建具体的TaskTracker(CommonTaskTracker, FrequentTaskTracker)
TaskTracker初始化时根据ServerScheduleJobReq中携带的所有worker地址创建ProcessorTracker:
protected TaskTracker(ServerScheduleJobReq req) {
// 初始化成员变量
//...
// 特殊处理超时时间
//...
// 赋予时间表达式类型
//...
// 保护性操作
//...
//此处初始化所有ProcessorTracker
this.ptStatusHolder = new ProcessorTrackerStatusHolder(req.getAllWorkerAddress());
// 构建缓存
//...
// 构建分段锁
// ...
// 子类自定义初始化操作
//...
log.info("[TaskTracker-{}] create TaskTracker successfully.", instanceId);
}
之后TaskTracker会开启一个Dispatcher线程处理分发任务,通过初始化时保存的集群中的ProcessorTracker进行任务分发: com.github.kfcfans.powerjob.worker.core.tracker.task.TaskTracker.Dispatcher
public void run() {
//...
// 1. 获取可以派发任务的 ProcessorTracker
List<String> availablePtIps = ptStatusHolder.getAvailableProcessorTrackers();
// 2. 没有可用 ProcessorTracker,本次不派发
//...
// 3. 避免大查询,分批派发任务
//...
// 4. 循环查询数据库,获取需要派发的任务
while (maxDispatchNum > currentDispatchNum) {
int dbQueryLimit = Math.min(DB_QUERY_LIMIT, (int) maxDispatchNum);
List<TaskDO> needDispatchTasks = taskPersistenceService.getTaskByStatus(instanceId, TaskStatus.WAITING_DISPATCH, dbQueryLimit);
currentDispatchNum += needDispatchTasks.size();
//此处通过迭代分发任务至可获得的worker中
needDispatchTasks.forEach(task -> {
// 获取 ProcessorTracker 地址,如果 Task 中自带了 Address,则使用该 Address
String ptAddress = task.getAddress();
if (StringUtils.isEmpty(ptAddress) || RemoteConstant.EMPTY_ADDRESS.equals(ptAddress)) {
ptAddress = availablePtIps.get(index.getAndIncrement() % availablePtIps.size());
}
dispatchTask(task, ptAddress);
});
// 数量不足 或 查询失败,则终止循环
//...
}
log.debug("[TaskTracker-{}] dispatched {} tasks,using time {}.", instanceId, currentDispatchNum, stopwatch.stop());
}
}
protected void dispatchTask(TaskDO task, String processorTrackerAddress) {
// 1. 持久化,更新数据库(如果更新数据库失败,可能导致重复执行,先不处理)
//...
// 写入处理该任务的 ProcessorTracker
//...
// 2. 更新 ProcessorTrackerStatus 状态
//...
// 3. 初始化缓存
//...
// 4. 任务派发
TaskTrackerStartTaskReq startTaskReq = new TaskTrackerStartTaskReq(instanceInfo, task);
String ptActorPath = AkkaUtils.getAkkaWorkerPath(processorTrackerAddress, RemoteConstant.PROCESSOR_TRACKER_ACTOR_NAME);
ActorSelection ptActor = OhMyWorker.actorSystem.actorSelection(ptActorPath);
ptActor.tell(startTaskReq, null);
log.debug("[TaskTracker-{}] dispatch task(taskId={},taskName={}) successfully.", instanceId, task.getTaskId(), task.getTaskName());
}
其他非master worker则直接通过akka接收TaskTrackerStartTaskReq请求并执行相应任务, 只有master worker会接收ServerScheduleJobReq请求并分发任务到其他worker节点中